Bilibili Favorites Planner 开源:把收藏夹整理拆成只读采集、本地复核和可审计任务包
我把 Bilibili Favorites Planner 开源了。
它是 B 站收藏夹整理流程里的“执行前准备端”:只读采集收藏夹数据,在本地生成分类建议和人工复核页,最后输出一个可以交给 Executor 执行的任务包。
项目地址:github.com/nj-zhangrui-arvin/bilibili-favorites-planner

为什么要单独做 Planner
收藏夹整理不是一个单纯的“批量移动”问题。
真正需要拆开的事情有三类:
- 先把收藏夹和视频元数据采集出来。
- 再用规则或模型给出分类建议。
- 最后由人审核后再执行。
如果把这三件事和写 B 站的执行器混在一起,风险边界会很模糊:到底什么时候只是读取,什么时候会修改收藏夹,什么时候 AI 建议变成真实操作,都不容易审查。
所以我把系统拆成两个仓库:
- Planner:只读采集、本地分析、人工复核、任务包生成。
- Executor:导入已审核任务包,负责真正写回 B 站。
Planner 以 Codex Skill 的方式分发。用户安装 Skill 后,把采集文件交给 Codex,Codex 会在本地生成复核页和任务包。Planner 不写 B 站。Executor 不做 AI 分类。中间用 reviewed-classification.jsonl 和 task-package.json 交接。
它解决什么
只读采集
Crawler 运行在已登录的收藏夹页面,只读取自建收藏夹和视频元数据。
本地复核
Planner 生成本地 HTML 复核页,支持搜索、分页、批量分类和新增分类名。
可审计交接
人工审核结果保存为 JSONL,任务包是明确、可校验、可追踪的 JSON。
风险隔离
Planner 不会创建、删除或移动 B 站收藏夹,写操作只发生在 Executor。
使用流程
flowchart TD
A["B 站收藏夹页面"] --> B["Crawler 只读采集"]
B --> C["evidence.jsonl"]
C --> D["Planner 分类分析"]
D --> E["review.html 人工复核"]
E --> F["reviewed-classification.jsonl"]
F --> G["task-package.json"]
G --> H["Executor 写回 B 站"]
第一步先安装 Planner Skill、Crawler 脚本和 Executor 脚本。采集时先跑测试采集,确认页面和下载正常;之后再跑全量采集。Planner Skill 会根据 evidence 生成复核页,人工确认后再生成任务包。只有 approved 的行会进入 Executor。
安装入口
- Planner Skill:https://github.com/nj-zhangrui-arvin/bilibili-favorites-planner/tree/main/skills/bilibili-favorites-planner
- Crawler 脚本:https://raw.githubusercontent.com/nj-zhangrui-arvin/bilibili-favorites-planner/main/scripts/bilibili_favorites_crawler.user.js
- Executor 仓库:https://github.com/nj-zhangrui-arvin/bilibili-favorites-executor
截图
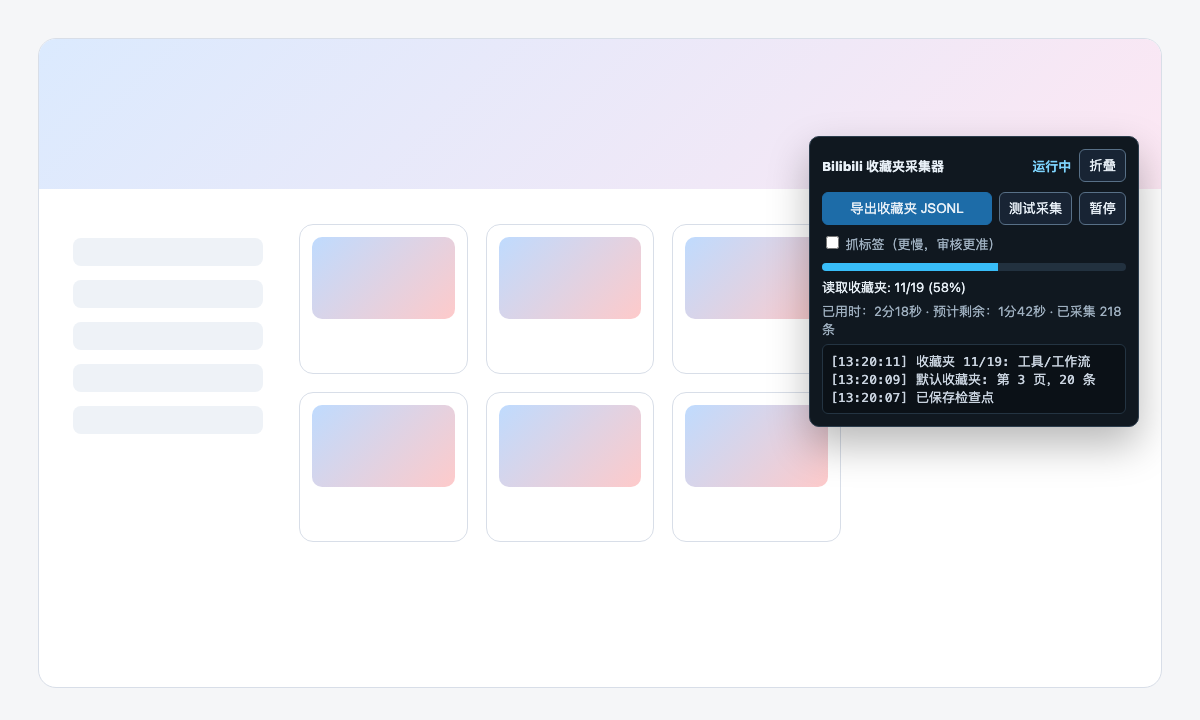
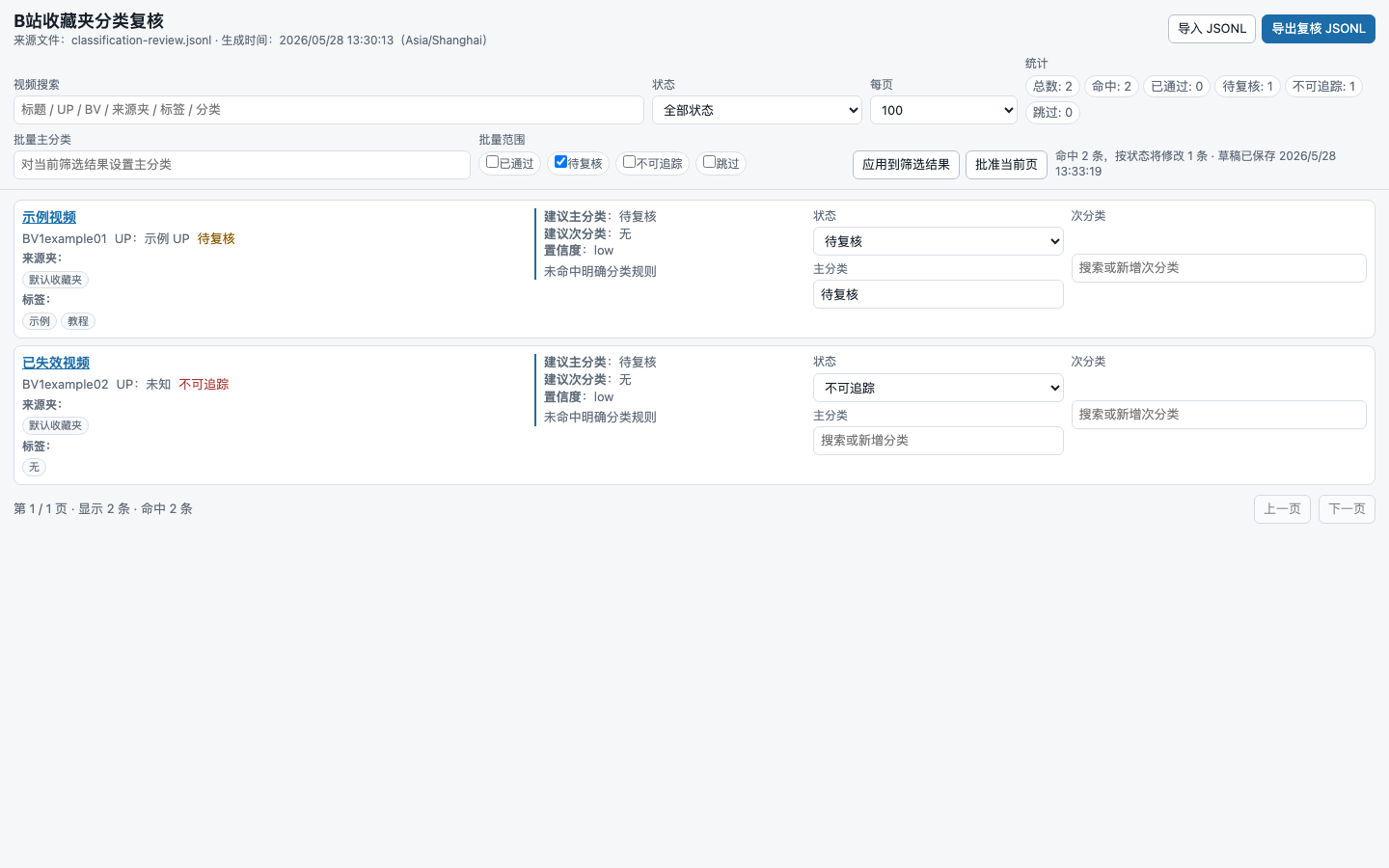
截图使用示例假数据,不包含真实账号、头像、收藏夹或视频列表。
安全边界
Planner 的默认边界是:
- 不要求用户粘贴 Cookie、SESSDATA、csrf 或密码。
- Crawler 默认不抓标签,减少请求量;需要审核辅助时可以手动打开。
- 默认只下载一个
evidence.jsonl,减少浏览器多文件权限提示。 - 复核页是本地静态 HTML,没有后端服务。
- 未经人工审核的建议不会变成可执行任务。
真正写 B 站的动作仍然交给 Bilibili Favorites Executor。
下一步
后续我会继续改进几个方向:
- 更灵活的分类规则配置。
- 可选模型分类适配器。
- 更适合大账号的复核体验。
- 更完整的英文文档。
- 和 Executor 的发布流程进一步对齐。
项目已经 MIT 开源。如果你也在整理自己的 B 站收藏夹,或者想把收藏夹变成更可维护的知识结构,可以从 Planner + Executor 这两个仓库开始。